Aridor, Guy,
Duarte Gonçalves, Daniel Kluver, Ruoyan Kong,
and Joseph Konstan. 2022. The Economics of
Recommender Systems: Evidence from a Field
Experiment on MovieLens. ACM Transactions on
Economics and Computation (EC2023).
Ruixuan Sun,
Ruoyan Kong, Qiao Jin, and Joseph A. Konstan.
Less Can Be More: Exploring Population Rating
Dispositions with Partitioned Models in
Recommender Systems. 2nd Workshop on Group
Modeling, Adaptation and Personalization (GMAP
2023) .
Ruoyan Kong, Joseph A. Konstan.
The Challenge of Organizational Bulk Email
Systems: Models and Empirical Studies. The Elgar
companion to information economics. 2023.
Springer Publishing.
09/2018 -- (Ongoing),
Grouplens Lab, University of Minnesota,
supervised by Prof. Joseph Konstan.
1. Towards an
Effective Organization -Wide Email System
1)In
organizations, Ineffective communication or
email overload could result in substantial
wasted employee time and lack of awareness or
compliance.
2)We study the reading behavior of employees
and interviewed representative organizational
senders to understand current practice, the
effectiveness of the communication channels,
and factors that lead to ineffective email
communication.
3)We found significant disorder and
ineffectiveness resulting in low read rates
and wasted employee time. A major factor
underlying these results is the disparate
views of different stakeholders on the use of
email channels.
4) I built a bulk email
personalization/delivering system which runs
for 2 months in a field experiment (python +
javascript + html), and a bulk email testing
platform which enables senders to evaluate the
time / money cost of each piece of information
within bulk emails (vue + html + firebase)
(https://bulk-comm.com/).
Ruoyan Kong, Chuankai Zhang,
Ruixuan Sun, Joseph A. Konstan.
Multi-stakeholder Personalization: A Field
Experiment on Incentivizing Employees Reading
Important Organizational Bulk Messages. To be
appeared in CSCW22.
Ruoyan Kong, Joseph A. Konstan.
The Challenge of Organizational Bulk Email
Systems: Models and Empirical Studies. The
Elgar companion to information economics
(under review). 2022.
09/2020 -
12/2020 Virtual Reality System for Invasive
Therapy
In invasive therapies such as
invasive ventilation and deep brain stimulation,
doctors face the challenge of planning,
performing, and learning complex surgical
procedures. VR systems were built to help doctors
plan surgeries. However, the previous VR designs
focused on navigation and visualization but not
risk estimation. In this paper, we introduced a
novel VR system for invasive treatment. Our
approach supports 1) 3D navigation of anatomical
models by a bi-manual miniature-world design; 2)
simulation of probe trajectory and calculation of
the corresponding risks; 3) visualization of
different layers; 4) visualization of
cross-sectional cutting by a plane. These
functions allow doctors to easily manipulate the
anatomical model and plan probe trajectory based
on the estimation of risks. https://www-users.cselabs.umn.edu/~kong0135/deepbrainvr/
09/2014-05/2016,
Department of Data Mining, National
Engineering Laboratory for Speech and
Language Information Processing,
supervised by Prof. Qi Liu.
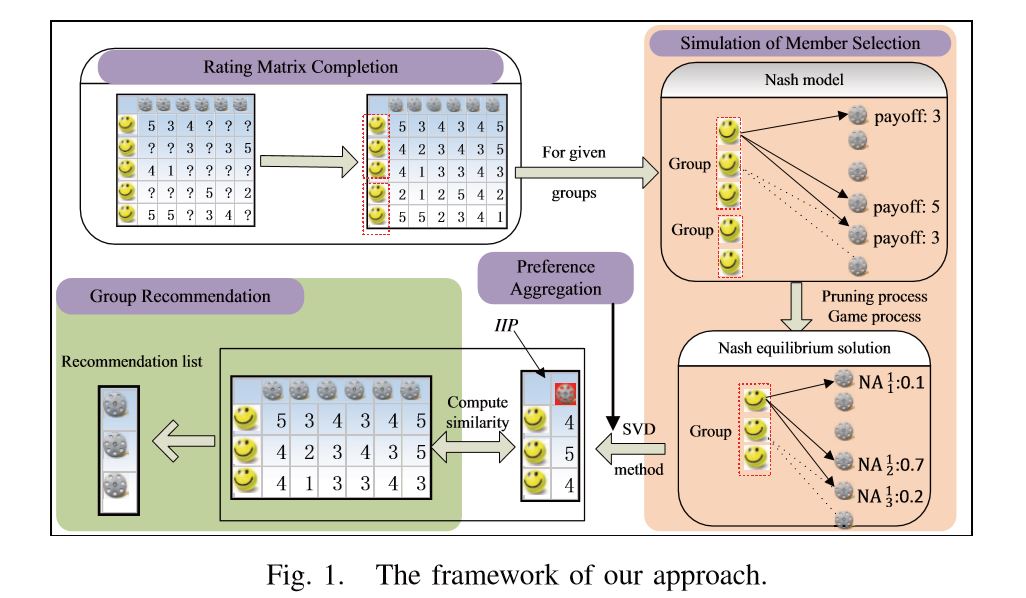
1. Design recommendation systems for group
users.
1)Group-oriented services such
as group recommendations aim to provide services
for a group of users. For these applications,
how to aggregate the preferences of different
group members is the toughest yet most important
problem.
2)In traditional preference
aggregation methods, such as preference
aggregation and score aggregation, the
interactions and fairness of group members are
still largely ignored. Therefore, these
aggregation approaches, which are unable to
figure out the optimal selections that can be
accepted by all members of a group, may lead to
unsatisfying services.
3) Inspired by game theory, we
propose to explore the idea of Nash equilibrium
to simulate the selections of members in a group
by a game process. The game process could
capture the group members’ interactions and the
Nash equilibrium solution considers the fairness
as much as possible.
4) Along with this line, we
first calculate the preferences (group-dependent
optimal selections) of each individual member in
a given group scene, i.e., an equilibrium
solution of this group, with the help of two
pruning approaches. Then, to get the aggregated
unitary preference of each group from all group
members, we design a matrix factorization-based
method which aggregates the preferences in
latent space and estimates the final group
preference in rating space. After obtaining the
group preference, group-oriented services (e.g.,
group recommendation) can be directly provided.
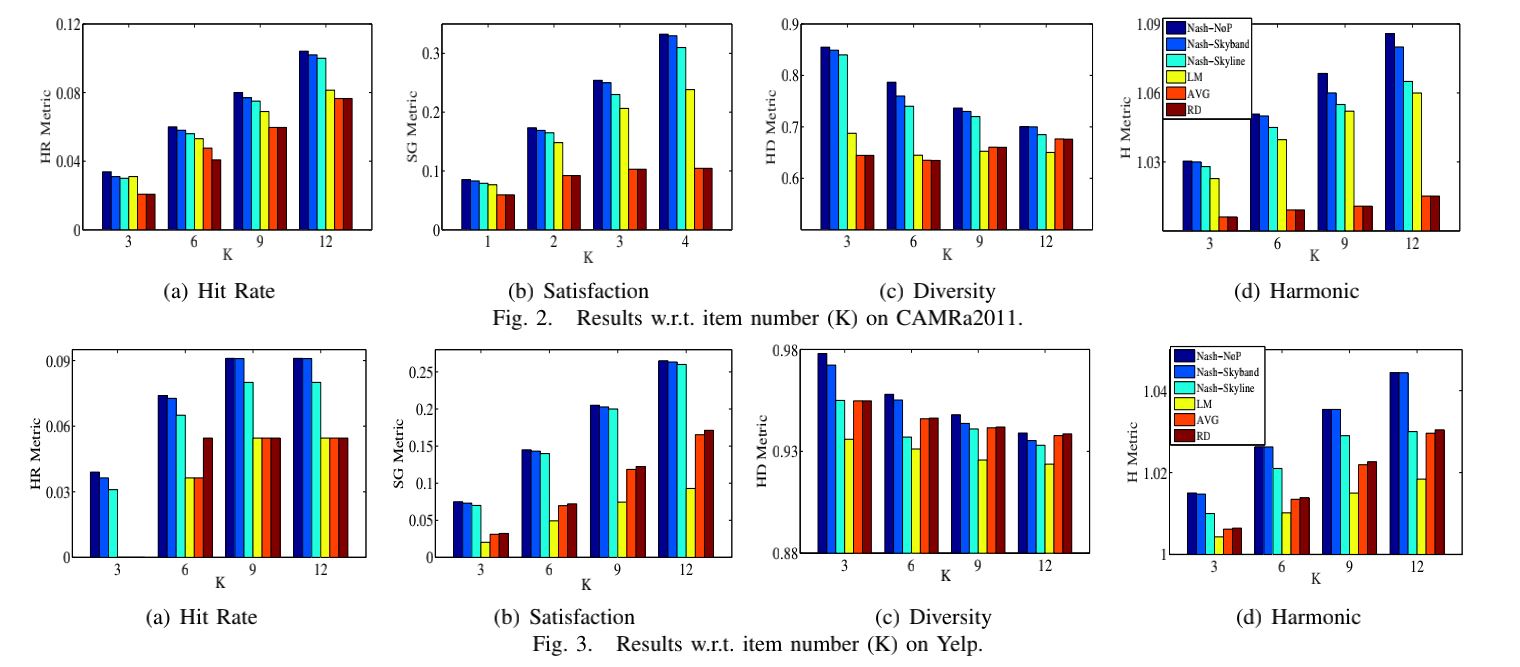
5) We examine our method on Yelp
dataset who has 22333 ratings. The results show
that the nash method has an outstanding
performance on 4 major metrics over other
methods.
6) Outstanding Student
Research, USTC, top 3% out of
undergraduates in USTC
Hongke Zhao, Qi Liu, Yong
Ge, Ruoyan Kong, Enhong Chen, Group
Preference Aggregation: A Nash Equilibrium
Approach, In Proceedings of the 16th
IEEE International Conference on Data Mining
(ICDM'16), Barcelona, Spain, 2016, 679-688
2.
Model of Incentives in Repeated
CrowdsourcingSystem
1) Repeated crowdsourcing
system refers to the crowdsourcing systems with
tasks which need to be conducted several times.
A problem needs to be solved in repeated
crowdsourcing system is how to set appropriate
incentives for requesters to maximize the
profits of requesters and workers.
2)Modeled the effects of
performance-contingent financial rewards in
crowdsourcing systems and provided answers to
the question: how does the anchoring effect
influence the cumulative profits of requesters and
workers?
3)– Proved that when the anchoring effect
coefficient r of requesters is smaller than 1,
the cumulative profits of requesters will
converge to a certain value increasingly, and
the value is negatively correlated with r. Tthe
optimal strategy for requesters is to increase
the wage slowly.
– Proved that when the
anchoring effect coefficient P of requesters is
smaller than 1 and r is smaller than P, the
cumulative profits of workers will converge to a
certain value increasingly, and the value is
negatively correlated with P.The optimal
strategy for workers is to increase the effort
slowly but keep it being larger than the
reaction of requester. Otherwise, the workers
should leave the game.
4) The crowdsourcing platforms
can use this model to design a principal scheme
to incentivize the participation of both
requesters and workers.
5) A-level undergraduate
thesis, top 10% out of undergraduates in USTC.
12/2016-08/2017
Department of Investment Management,
Derivatives-China, supervised by Mr.
You Zhang and Dr. Ling Long.
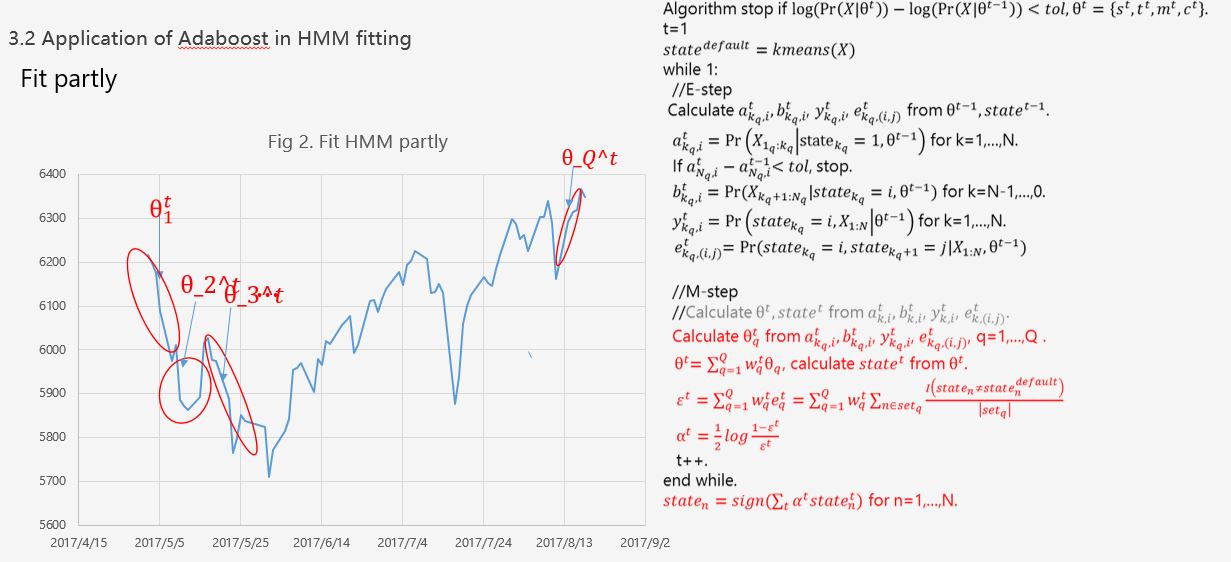
1. A Half-supervised Hidden Markov
Model to Forecast Index Futures.
1) In order to predict the
trend of markets precisely to make profits, we
use the hidden Markov model (HMM) to divide the
market into N different status.
2) The Baum-Welch algorithm
that is currently used to estimate the HMM only
converges to the local solution of HMM and can't
be applied in the real trading because its
result will change every time we optimize it. We
design a parallel-serial estimation algorithm to
solve this problem and got an approximate stable
solution. This is a creative work which has not
been done before.
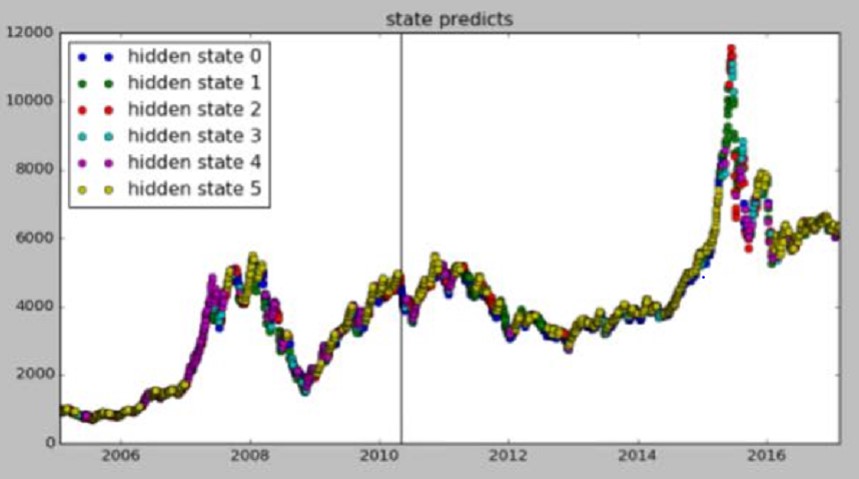
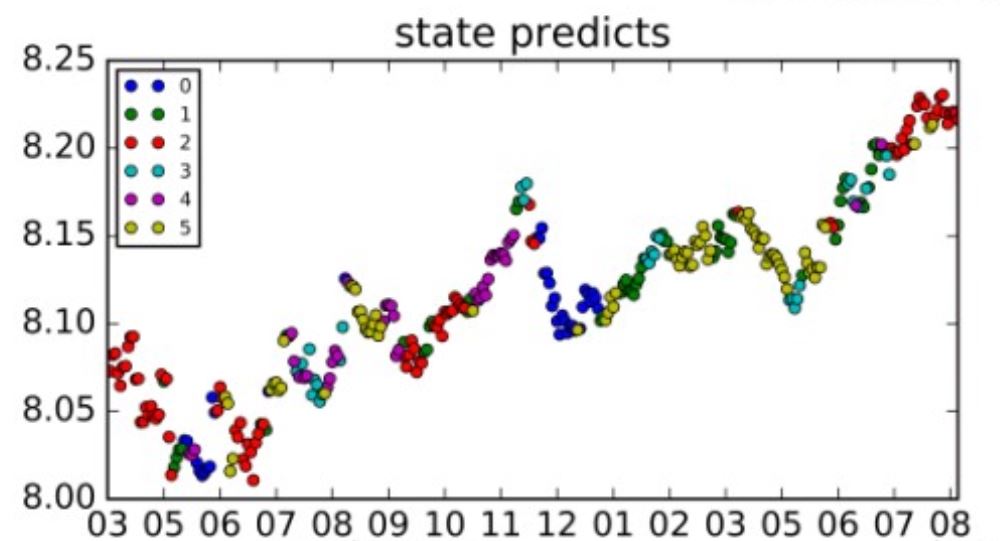
Fig 1.
The status of 399905.SZ predicted by HMM
(which gives a green warning before
the great market crash in 2015)
We can
find out that HMM has a good performance in
describing the market.
3) The
estimation of HMM is unsupervised and may not
towards the direction which we need to make
profits from. Also, the estimation process is
largely influenced by the big trend of the
economy, for example, the big trend of the
market from 2006 to 2015 is increasing, then
HMM will tend to give an increasing status
instead of taking the local situation of the
market into consideration. We need to build a
market timing strategy which can be applied to
different market environments.
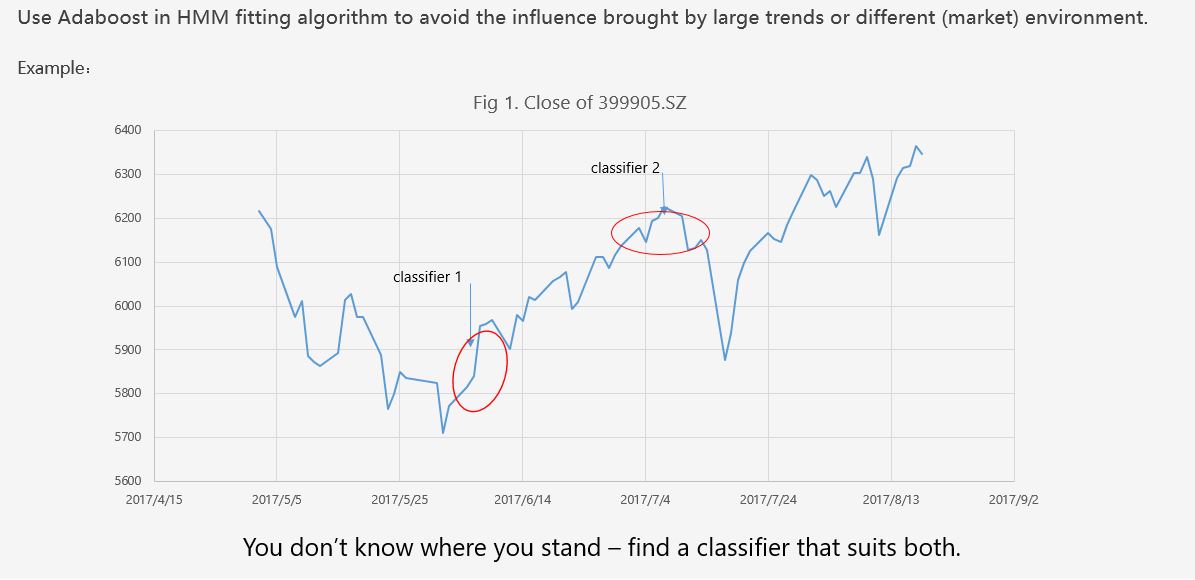
Because
Baum-Welch algorithm and HMM include dependent
time series, we can't solve this problem by
simply enlarge the weights of negative
samples.
We use an
AdaBoost-subsection estimation method to solve
this problem. To our knowledge, this work has
not been done before.
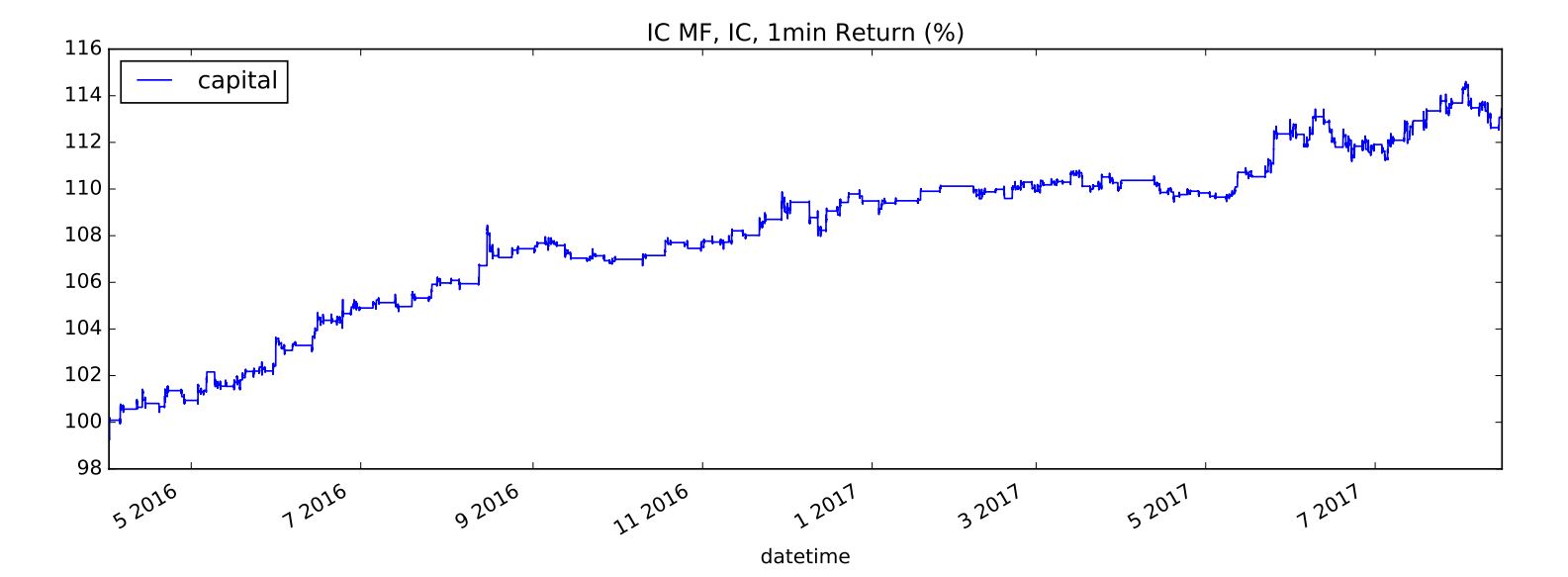
Our
algorithm has an outstanding performance in
predicting the trend of the market.
It can also bring a
consistent return.
2. Application of Markov
Chain Monte Carlo (MCMC) and HMM in GDP
prediction.
1) If we want to apply
HMM in GDP prediction, we will find out that
the large scaling of features (E.g. the
overall GDP of last year) will keep us from a
good estimation of HMM, especially the means
matrix and covariance matrix in HMM. We need
to find a method to avoid this drawback of HMM
estimation algorithm.
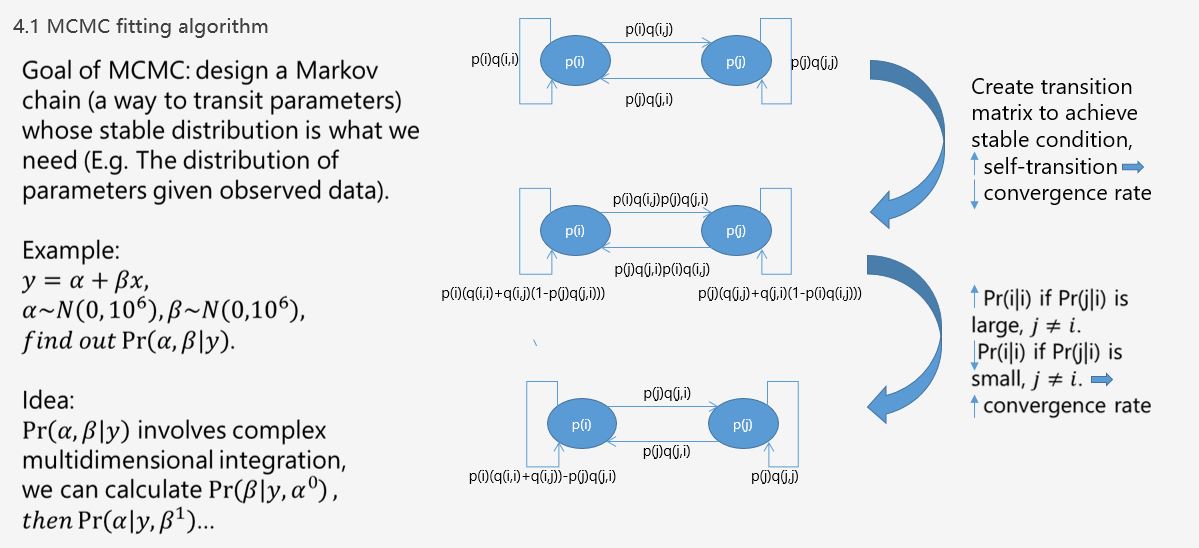
2) We use Markov Chain
Monte Carlo (MCMC), which we can input our
prior information about the distribution of
parameters in, and Sobel Sequence can generate
highly independent random sequences. MCMC has
a Markov process which will converge to the
best estimation based on the posterior
distribution and the prior distribution of
parameters.
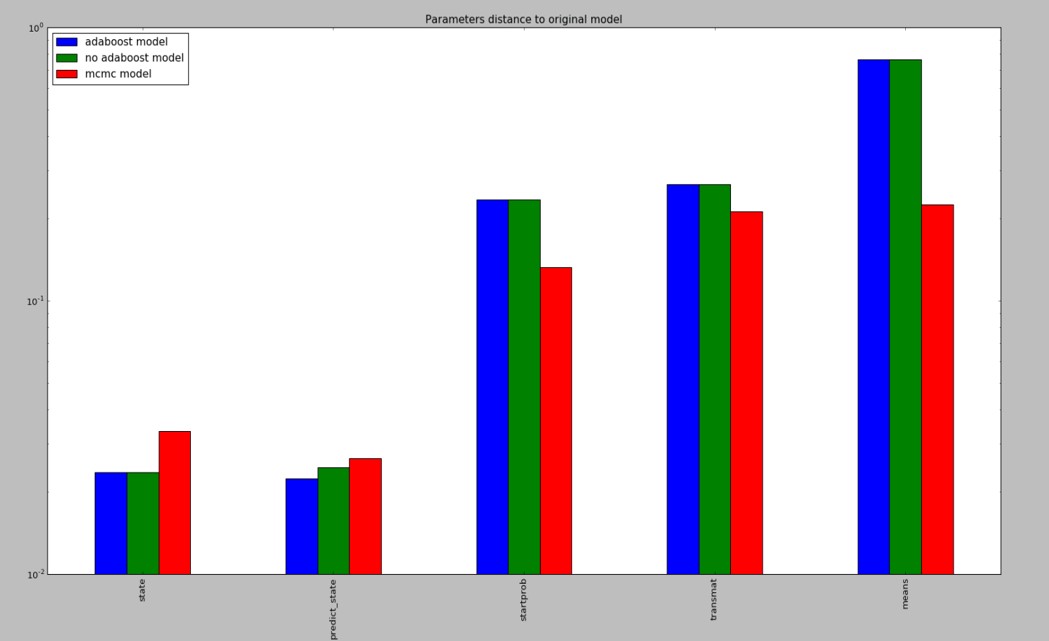
3) We can
see that MCMC has a lower error rate in the
estimation of parameters who have high
dimensions and large scalings.
Thanks to the beneficial suggestions from
Prof. Thomas J. Sargent.
09/2017-
06/2018 School of Economics and Management,
Tsinghua University, supervised by Prof.
Michael R. Powers.
1.A Risk
Finance Strategy Paradigm with Copulas
1) When dealing with risks, companies can
choose to pool, hedge or avoid them. However,
the traditional risk finance paradigm can't give
a quantitative method to describe the condition
of the application of these strategies.
2) In our prior work (Risk Finance for
Catastrophe Losses with Pareto-Calibrated
Levy-Stable Severities, Michael R. Powers), we
used stable distributions to model this
paradigm. In this paradigm, we assume that
losses are independent, which is consistent with
our real experience.
If we assume losses are correlated, the
paradigm would be different. The reason for
taking correlation into consideration is that
correlation between losses will affect people’s
decisions about whether to hedge or pool the
loss portfolio L. For example, a group of marine
traders wants to limit their ship sinking risks.
If their routes are different, their ship
sinking risks are uncorrelated and they can
divide their merchandise into portions and
distribute across all ships (pooling), then no
trader will be devastated by a sinking of one
ship. However if their routes are the same,
their ship sinking risks are correlated (their
ships may be attacked by hurricanes or tidal
waves together), then pooling will be useless in
this case because they will be devastated by the
sinking of ships altogether and they should
choose to hedge this portfolio like to buy
insurance from an insurer (who can afford this
because he can pool the risks from different
marine trader groups).
3) We also designed a parallel-serial numerical
algorithm to get Fourier-analytic risks for
levy-stable variables.
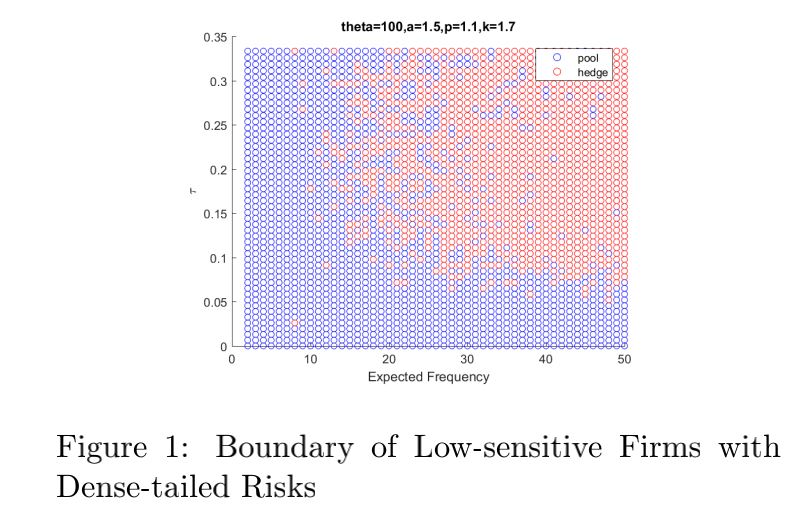
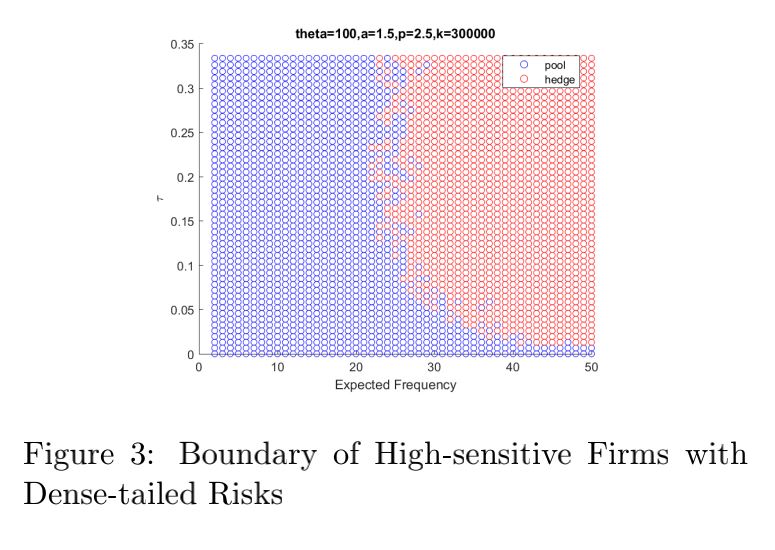
4) Heavy-tailed case: As p increases, the firm
will be more sensitive to risks, and the lower
boundary will decreases more rapidly as the
expected frequency increases. It can be observed
that when p < 2, a firm will still choose to
pool when the dependence between risks is as
small as the expected frequency increases.
However, when p > 2, as the expected
frequency is large enough, the firm will always
choose to hedge no matter the dependence is
small or not.
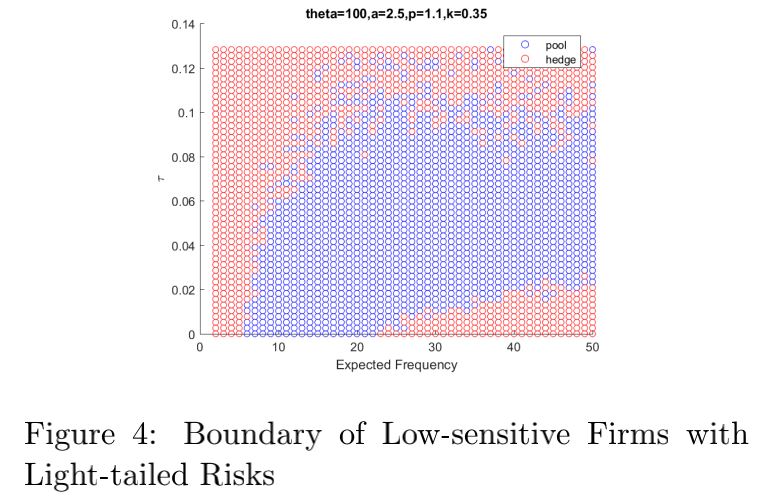
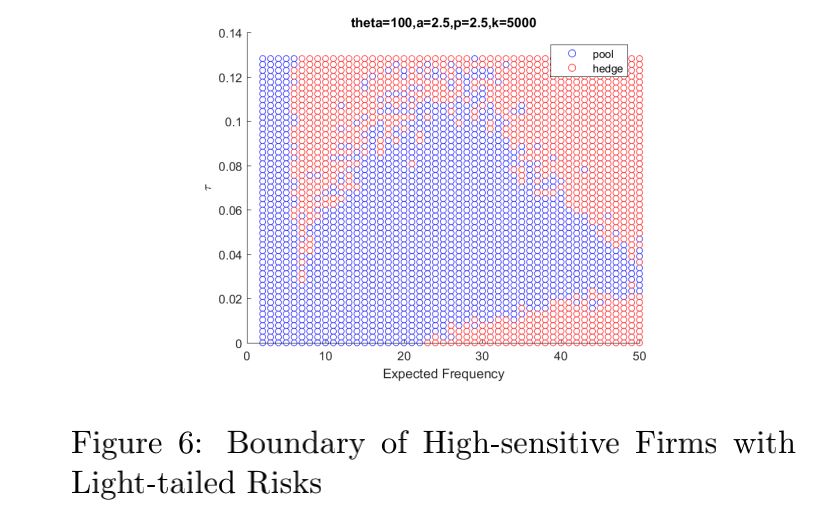
5) Light-tailed case:
When the expected frequency become a little
larger, the firm will be able to accept higher
dependence(TypeII). It may be attributed to that
a little larger frequency offers more choice for
the firm to distribute the risks.
When the expected frequency achieves some
point, the firm can only accept lower dependence
as the expected frequency increases(TypeI). It
may be attributed to that higher frequency will
increase a firms’ overall risks to a large
extent. And an interesting inverse lower part
appears(TypeIII). In this part, the firm will be
exposed to high frequency and low dependence
risks, and it will choose to hedge to diminish
the risks brought by the high frequency.
As p increases, the firm will be more sensitive
to risks, and the lower part of the TypeI
boundary will decreases more rapidly as the
expected frequency increases. When p > 4/3,
the hedging districts in the right-upper corner
and in the right-lower corner will merge when
the expected frequency is large enough, which
means that the firm will always choose to hedge
when the expected frequency is large enough.
When p < 4/3, there will always be a room
left for pooling no matter how larger the
expected frequency will be.